


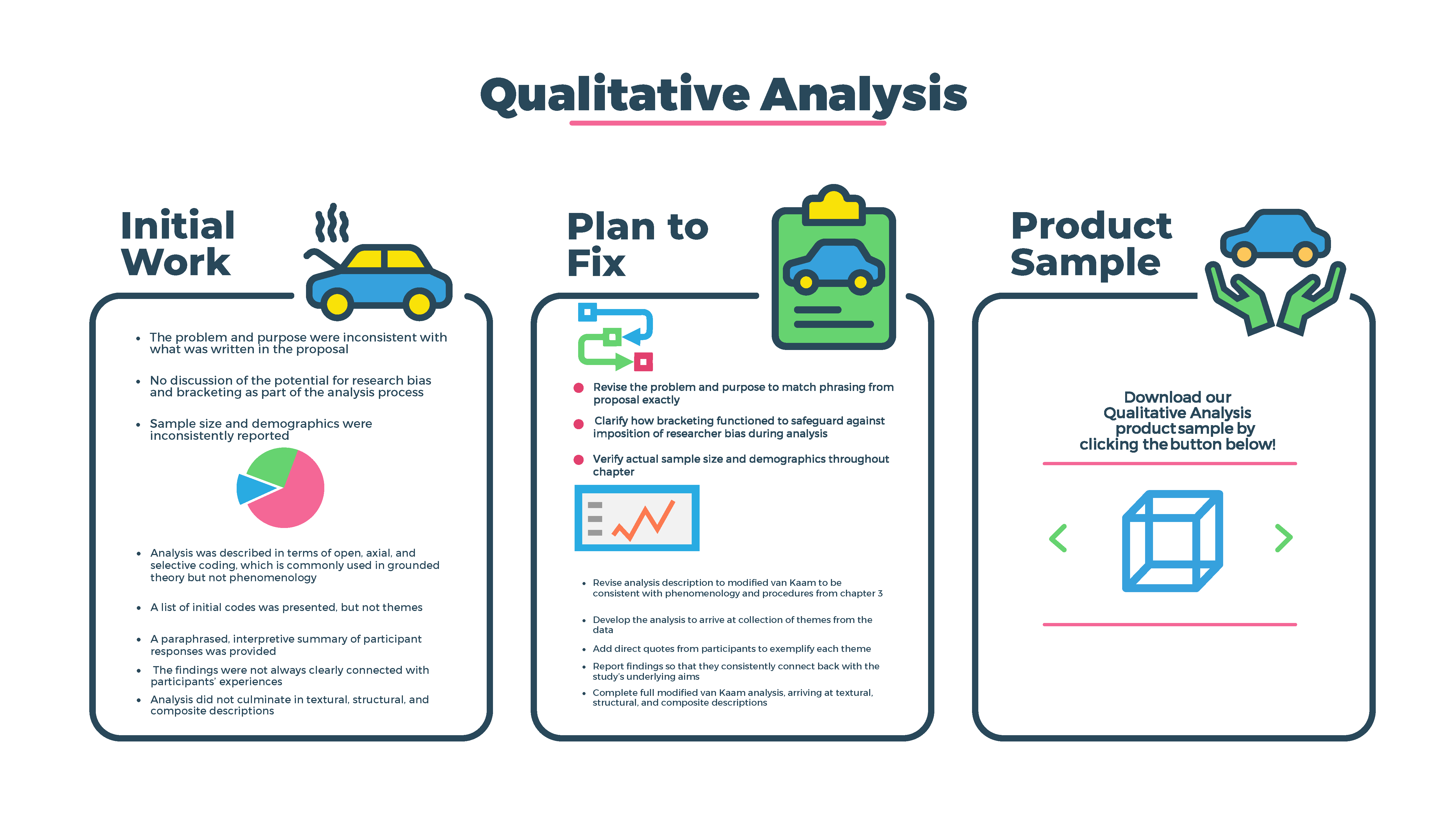
Qualitative Analysis
While Precision started out as a statistical analysis firm, since then we’ve expanded to provide the most comprehensive qualitative research support available for doctoral candidates and established academic researchers alike. We are the only firm to provide comprehensive assistance with qualitative methodology development, data analysis, and drafting results. This means that, if you’re seeking any support to perform your qualitative analysis and interpret your results, we are uniquely qualified to assist you–regardless of your specific research design.
There are 3 ways to initiate contact with us:
- Please review and submit the following form. Someone from our team will contact you within 1 hour (during business hours), or at your requested time.
- Our consulting team is available via telephone Monday through Saturday from 8:00 A.M. to 8:00 P.M Eastern Time. Feel free to call us on (702) 708-1411!
- We also pride ourselves on our very prompt and in-depth e-mail responses, 365 days per year. We normally answer all urgent queries very promptly, including late-night and weekend requests. You can email us at Info@PrecisionConsultingCompany.com
Please be prepared to discuss the specifics of your project, your timeline for assistance, and any other relevant information regarding your proposed consultation. We respect the confidentiality of your project and will, at your request, supply you with a Non-Disclosure Agreement before discussing specifics.
Our qualitative research experts are highly experienced with qualitative analysis software, including NVivo 11, ATLAS.ti, MAXQDA, and Dedoose. As qualitative research becomes more complex, with IRB documentation requirements, more participants, audio and video recording, data coding, and multiple levels of analysis, universities are encouraging students to use these software tools. As full service dissertation consultants, our expertise with these platforms allows us to help you with each stage of the analysis process so that your results are robust and provide clear insights into your research questions. We know that a clear analysis process and results discussion are the best way to get your completed research approved sooner!
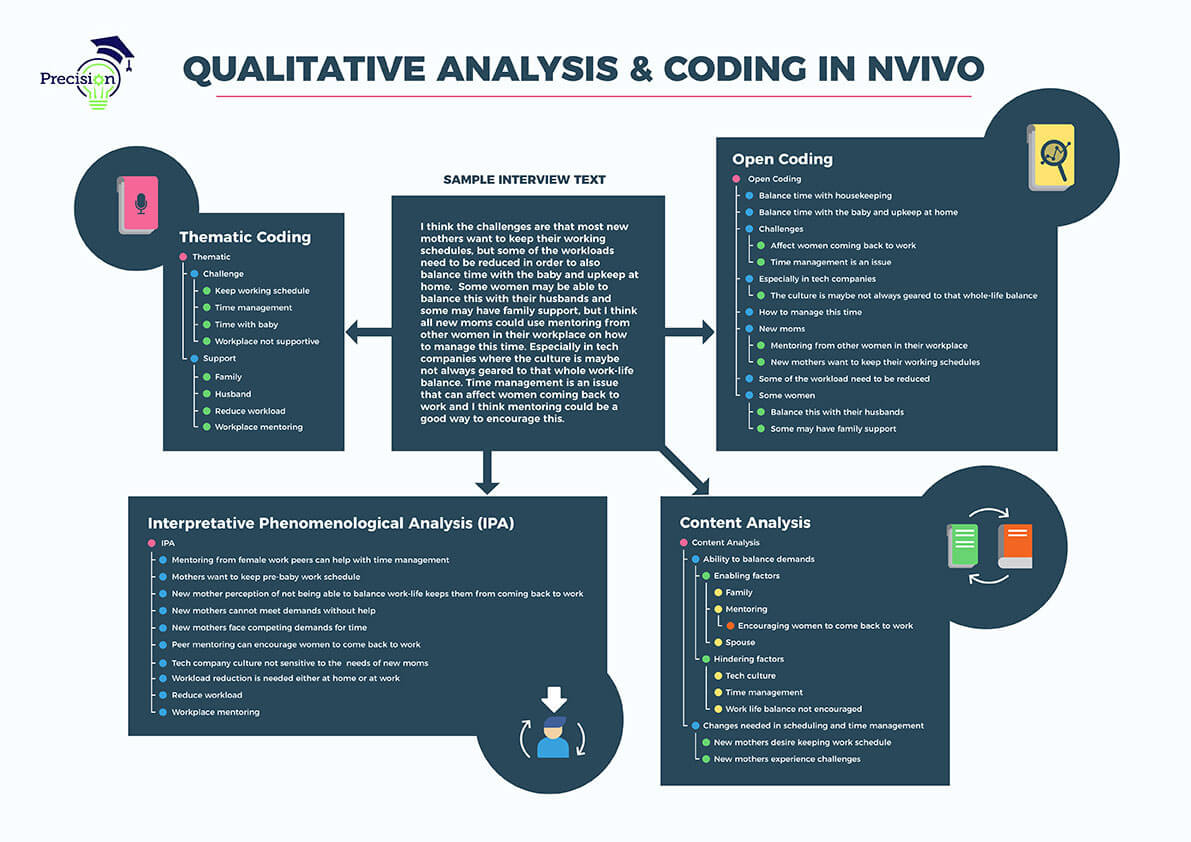
Precision Consulting has helped our clients comprehensively analyze their qualitative data utilizing a number of different methodologies. Some of the most frequent qualitative research and analysis methods are described below, though we are also well versed in hermeneutical studies, narrative analysis, quasi-statistics, and more. After more than 17 years providing dissertation assistance, we’re knowledgeable in virtually every qualitative research and analysis method!
- Phenomenology: The overall aim of phenomenology is to derive an understanding of essential meanings as perceived by participants, and constructed through interpretation of their lived experiences. This methodological approach necessitates in-depth interviews that usually last from 90 to 120 minutes. Typically for doctoral-level research, phenomenological studies also have a small number of participants. These can be as small as 6 to 10, but some doctoral candidates decide to interview up to 20 participants. This methodology is used to look for patterns and trends by identifying shared beliefs that have yet to be addressed by existing literature, so it is important to find dissertation consultants who understand the unique characteristics of a phenomenological study and shed any preconceived notions when engaging in appropriate qualitative analysis.
- Case studies: Case studies take a more holistic approach to qualitative research. They can be descriptive, exploratory, explanatory, so they are certainly one of the more versatile qualitative methodologies. The overall aim is to understand complex processes as they naturally occur within specified bounded systems or groups. For a single case study design, the aim is to explore participants’ experiences of complex phenomena in a single setting or group. For a multiple case study design, the aim is to compare experiences across different settings, such as different business environments or schools. A main consideration for data collection for case studies is triangulation. You need multiple data sources (such as interviews, written responses, observations, focus groups, and/or artifacts) to assess for degree of data convergence across sources–and to conduct a thorough thematic analysis to provide robust results for your research questions.
- Grounded theory: The overall aim of grounded theory is to construct a theoretical model that explains phenomena of interest, based on the direct experiences and perspectives of participants. Data collection involves interviews with participants who are selected using theoretical sampling, meaning they are deliberately chosen based on expectations of their abilities to “fill in” any gaps in understanding as you construct theory from the data. This design, in particular, involves an iterative process in which the researcher moves between data collection and data analysis, with insights gained through analysis phases then guiding the focus of future data collection. This iterative process then furthers the continued theoretical sampling process, as new participants are sought to elaborate more fully on as yet undeveloped components of the theory as these emerge through qualitative analysis.
- Ethnography: The overall aim of ethnographic research is to develop an in-depth understanding of complex social and/or cultural phenomena within specific settings or groups, through direct immersion in and interaction with the setting or group of interest. This is a fundamentally immersive form of qualitative research, in which the researcher’s own experiences, perspectives, and interpretations are central to the findings and conclusions of the study. Data collection must take place over an extended period of time to develop a full appreciation of the cultural complexities as they occur within the group of interest. This is often a combination of immersive approaches, such as participant and nonparticipant observation, as well as interviews, and review of archival documents, artifacts, or symbols that have relevance for the group of interest.
- General qualitative inquiry: If you don’t want to be constrained by a specific methodology, or if your design does not fully mesh with those described above, you can follow a general qualitative inquiry design. This design allows for greater flexibility in terms of sample size and data collection procedures, and can focus solely on interviews or use multiple forms of data to identify categories during the analysis process. Because we have experts in so many fields, we are well equipped to identify trends, themes, and patterns to classify data from many different disciplines. In addition, our expertise with NVivo, MAXQDA, ATLAS.ti, and Dedoose are special assets to anyone conducting content analysis, which involves a theory-driven quantification of traditionally qualitative research materials, such as audio, video, or transcribed data.
Let’s keep it a secret…
Before sharing your materials with us, we will send you our Non-Disclosure Agreement, which guarantees that your work materials, and even your identity as a client, will never be shared with a third party.Hello! Welcome to Precision’s NVivo tutorial!
NVivo is the most popular qualitative analysis software. It allows greater depth than Atlas.ti and more flexibility than MAXQDA. Today, I’ll discuss the basic terms and processes needed to do basic coding for qualitative data analysis.
Before we begin, let me mention that we’re one of the only academic consulting firms that take on qualitative research from start to finish! We can help you not only with the analysis that we’ll talk about in this tutorial, but also the qualitative methodology that gives rise to this work.
If you’ve stumbled here by accident and are looking for statistical analysis, then SPSS is your program. Check out our video on quantitative methodology for help tailored to your needs!
Now, let’s dive in and open NVivo to create a project.
So if you click the QSR Nvivo icon on your desktop it will open the application. On first launch, the NVivo User dialog box will display.
By default, your Windows user name is displayed in the Name field. You can update the name if required. If you are sharing this Windows login with another user, enter your own name and in the Initials field, enter your initials. Click OK.
Since this is not my first project, I will just click on the Blank Project button and a dialog box is displayed. I will enter a name for the project
In the description field, I can enter a description of my qualitative project. This can include information on the objectives of the research.
To select where the project will be saved, click the Browse button and select the appropriate folder. I like to save my NVivo file with the materials for the project all together.
Once you have your folder chosen you click save and then, click OK.
The NVivo window is displayed with the name of your project in the Title bar and your user initials in the Status bar.
Defining User Interface Terms and SpaceThere are 3 Types of views in the user interface.The first type of view is Navigation View:On the left side of the screen, you can navigate your way around your sources.The types of sources will be defined later in this tutorial.The second type of view is the List View:On the top portion of the workspace screen, click on the VIEW tab. The list view allows you to see a list of the contents of the sources you click on in navigation view.The third type of view is the Detail View:This makes up the center of the screen, extending to the lower right-hand corner. This is where you see the content of your sources, and is where your qualitative analysis actually takes place!
In detail view, you can open multiple tabs of different sources. The tabs are in the top left hand of the detail view screen.
When you are on the HOME tab you should be able to see the Navigation View on the left and the Detail View taking up most of your work space.
As you can see, it’s already starting to get tricky! For help in navigating this new program for your dissertation, know that we’re here – just call or email!
Okay, Types of Sources
In NVivo, ‘sources’ is the collective term for your research materials—anything from handwritten diaries to video recordings of group discussions.
After creating a project, you can gather your research data in the following ways:
Import Internals
These are your primary sources that may include:
Documents in text (.txt), rich text (.rtf), portable document format (.pdf) or Word (.doc) format. For example, interview transcripts, emails, journal articles and so on. Many dissertation projects contain many different sources of data — they help make your eventual results much more robust.
To import your data, click on the DATA Tab at the top of the work space. Then, click the type of source/file you need to import.
Once you are in the folder where your materials are, you can gather multiple sources at once, and then click open, and then click ok.
Now your data sources should appear as a list in the center of your work space.
If you want to be sure to keep a particular group of sources separate from others, you can create folders for your dissertation to save the information in. You can edit these at any time.
So here I’m going to save group interviews for my qualitative analysis…and move them over there into the folder. Then, you would go back in and get additional sources in the same way.
For each source, each folder, you will need to go through and add all of the sources…here I have all Word documents so I was able to highlight those and import them all in groups. If you have to import a PDF, a survey, audio files, you will have to import each type separately for your qualitative research. NVivo doesn’t allow you to import different types of data sources at the same time.
This work can be difficult, so reaching out for consulting as you navigate this rather complicated program for your dissertation is natural!
You can also create documents directly in NVivo. You would create documents for files that you cannot import—handwritten diaries, books, PowerPoint presentations and so on.
Okay, documents! To create an Internal document, click on the CREATE tab at the top of the work space.
You will be given the option of creating an Internal document, a link to an External document, and audio/video sources as well as the option of creating a new Node, Case, or Relationship.
Click on the type of document you need to create and follow the prompts from there.
Now we can move on to the key units of your qualitative analysis. Those key units are called Nodes and there are 5 types of nodes:
The two most commonly used nodes are referred to as Free Nodes and Hierarchical nodes.
Free Nodes means that all nodes are equally important and there is no hierarchy in the arrangement of the nodes.
To create a free node, click in the nodes to the left, then you right-click and a drop-down list will appear…you click on new node and then you get a dialog box…so we need to give the node a name (e.g. node 1). Then click OK.
It will appear in detail view in the center of your screen.
The second type of node is Hierarchical and is referred to as either a Tree Node or a Parent Node -these are used to set your general categories/initial groupings.
To create a parent and child node you repeat the action used to create a free node, then right click on it to create and name a child node. So, right-click, and do node 2…ok. Then on the node, right-click that and then we have child-node 1. You click, ok, then you have a parent node and a child node.
You can add as many sub/child nodes as needed. On occasion, you might even have sub-nodes for your child nodes.
First, though, I would like to say that if you’re having a hard time with any of these initial steps – or the ones that come next for your dissertation! – just give us a call or send an email. We’re unique among consulting firms – we provide help with all types of types of qualitative research and analysis.
Back to nodes! The other types of nodes – used less frequently – are:
- Cases (for demographic information)
- Relationships (nodes that describe the connection between two project items)
- Matrices (a collection of nodes resulting from a matrix coding query)
These nodes are used less frequently because they require a higher amount of data and more complex coding approaches.
Okay, now that we’ve got a basic lay of the land, we’ll talk about using coding to simplify the qualitative analysis that comes next! This is where you’ll start to work with all the interviews, focus group data, and other documents to assess emerging themes. I should mention here again that there are a lot of terms! For someone new to coding, it can be overwhelming, and reaching out for dissertation help can be a real time saver for this step!
Again, next is the analysis itself. Simple Coding- As a process, coding allows you to gather together all the material related to a topic.
NVivo allows both simple and advanced coding methods. In this tutorial, we will only cover the two most common types of initial coding to get you started on your qualitative analysis.
To begin coding, click on SOURCES on the bottom left-hand navigation window. Then double-click on the specific source you want to code. I’m going to go to the group interviews, to the first group there and then it displays in Detail View over here on the right.
2. When you click back on NODES you can have a view of the nodes that you are using and source that you are coding.
You will want to adjust the columns to adjust your view – giving more space to the source data.
You do this by clicking over here on the grey arrow and that minimizes the Navigation View on the left-hand side.
Now you can see the nodes you create on the left and your source data on the right. For convenience, you can have multiple source tables open at once in the detail view, like so.
There are a few ways to select the source data and move it over into nodes, so let me show those to you now.
The first way is to left click and highlight the source data, then drag and drop it into an existing node, like so. OR, you can highlight the data text, and drag it to the node area-you will be prompted to enter a name for the node. Finally, you can highlight and right-click on the data to see a drop down menu-you click code and enter the title of the new node from there. You click ok after naming and it will appear in the node detail screen.
If you open the node (by double- clicking), you can see coded content.
If you accidentally code text that you don’t want to keep coded you can highlight the selected text, right-click, and go down to choose of ‘Uncode’-from this node.
Now let’s briefly look at the two most common types of initial coding, which are called Open and In Vivo Coding.
With open coding, you look for units of meaning within the data and code them into broad categories (e.g. a technology lesson can be coded by types of content as well as the method of teaching).
It is important to do this type of coding at the beginning for two very important reasons. One, it familiarizes you with your data and good qualitative research is gained by deep familiarity with the data. It also helps to make your thesis or dissertation defense much easier.
The second reason it is important NOT to skip this, is that allows you to break down the data into the smallest possible units, and this in turn works to prevent you from coding what you want to see rather than what’s there in the participant’s words. In other words, it’s a barrier to interpretive bias. It’s common to seek dissertation help to provide a check on your work or to help avoid this and other kinds of bias.
As you discover new units of meaning you either code them to existing categories/sub-nodes OR create a new category (parent node) or sub-node.
With In Vivo coding, you directly code the source data/participant’s words. This approach is especially useful for Grounded Theory, Ethnographic, and Phenomenological research projects because they draw so heavily on the experience and perspectives of the participants.
To code In Vivo, you highlight the text you want to code, right click on it, and choose the ‘Code In Vivo’ option. The text will appear on the left as a non-hierarchical node.
To move the In Vivo text into an existing node, click on the coded node and drag it to the desired category/child node.
When you click on the node plus sign it will display the coded material.
And that covers basic first round coding. Of course, most qualitative analysis works through at least three rounds of coding to sift the data into final categories and themes.
While a precise coding plan is usually developed at the dissertation proposal stage, it isn’t always. Talking with a consultant at any stage can be immensely helpful.
Now that you are familiar with sources, nodes and initial qualitative coding steps you can begin to explore other features for your analysis, like
- Querying your data
- Creating charts
- Running reports
- Exporting data
To Query your data, you
Can either click the QUERY tab at the top of the work space
OR
Queries in the bottom left-hand of the Navigation View.
The two most common queries are coding queries and word frequency queries.
A Coding Query: Gathers content based on how it was coded. For example, showing all the content where participants mention selected terms.
In the QUERY tab click ‘Coding’ option and a window will appear in detail view. You can choose ‘All Sources’ or ‘Selected Items’ for where you want the query to search.
You can choose ‘All selected nodes’, ‘Any selected node’ ‘Any case where’ to further narrow the search terms.
A Word Frequency Query: Lists words and the number of times they occur in selected items. Seeing which words appear most frequently can help you to identify themes and concepts.
In the QUERY tab click the ‘Word Frequency’ option and a window will appear in detail view. You can choose ‘All Sources’ or ‘Selected Items’ for where you want the query to search. You can choose the number of words to be displayed (e.g. the 1,000 most frequently used words’)
Click RUN QUERY- your results will appear, here, in detail view. You can choose to save the query to the project – or- exit out of it without saving.
Two advanced types of queries are Matrix Coding Queries, and Compound queries. Though we do not cover these in this tutorial. It’s good to know they exist and what their purpose is.
Matrix Coding Query: Creates a matrix of nodes based on search criteria. For example, showing attitudes about volunteering by age group.
Compound Query: Combines text and coding queries—search for specified text in or near coded content.
I should mention that many qualitative research projects do become a lot easier using these tools, so please call us – we’ll provide timely help to get you through this difficult step!
Moving on now to creating simple charts for your dissertation manuscript — there are multiple ways that NVivo can display the data from your qualitative analysis in chart form.
In the EXPLORE Tab – Select the chart you want to create and click on it. You will be prompted to name the chart.
Select the data you want to chart in the options provided. These options will change depending on the chart you want to generate.
Here I will show you the easy options for a hierarchy chart. You can create a hierarchy chart for specific nodes OR for the whole project.
To create a hierarchy chart for specific nodes/subnodes, click the relevant nodes, right-click, and from the drop-down menu the visualize data option. You should see the results in detail view.
To do the same chart for the whole project, you would go to the Explore tab, click on Hierarchy chart, and, as I’m doing here, follow the prompts. The results again, appear in detail view.
Now, let’s cover Running Reports. In the EXPLORE Tab you can also run different types of reports: project summaries, source summaries, node summaries, relationship summaries, and attribute summaries.
Project Summary: A list of the project status in terms of the items it contains. This can be useful for communicating or recording the overall progress of your qualitative analysis project.
Source Summary: A list of the sources in the project including the number of nodes that code them. It also contains information about paragraph and word length.
Node Summary: A list of the nodes in the project including the number of sources coded at each node. This can help you to see which themes or ideas are occurring more than others.
Relationship Summary: A list of relationships organized by relationship type. This gives you an indication of how much coding has been done for each relationship type.
Attribute Summary: A list of attributes and the number of cases assigned to each attribute value. This is a useful way of checking for consistency and balance in the project sample.
These reports can be really helpful if you’re conducting a mixed methods study. See that tutorial for more information!
To run a report:
At the top left of the EXPLORE tab, click on New Report and choose Report Wizard.
Choose from the presented options at each step (total of 8) in the Report Wizard.
Select the data you want to a report on in the options provided. These options will change depending on the report you want to generate.
Now that you have all of your data coded and charted, you will need to know how export all your hard work.
As with most of the functions in NVivo, there are multiple ways to export your qualitative research results.
One of the ways I find most useful to share my coded data with others, is through exporting the coded nodes as Word.doc files.
To do this you click on the Data tab at the top of the workspace, then select the nodes or subnodes you want to export by clicking the extract items symbol up here. A menu will open, prompting you for how you want the information exported.
You can choose to export the entire content in html or web format, in reference view, or summary view. Each view type uses different file types.
To export the nodes in Word.doc, you choose reference view, Word doc, then select where you want the files to be saved by clicking browse, and ok.
The other way to export data that I find useful is by exporting your codebook-this contains a list of your nodes and any descriptions you created for them — this will help as you craft the results section of your dissertation.
To use this function, you click on the Data tab, click codebook, browse to select save location, and click the box here if you want the number of sources and references included in the codebook- click ok.
And there you have it, all the basic functions of NVivo. To recap,
we’ve gone over: how to open and save your project, how to import your data, what different types of Nodes are and how to set them up, the basic types of open and In Vivo coding, how to query, create charts, run reports on your analyzed data, and export your results.
Whew! That’s a lot of steps! Thank you for following along! I know that I’ve shared a lot to help unpack this part of the dissertation for you, but you might still have questions. Please know that we’re here to help you navigate both a new program and a new process! We can help with your qualitative analysis, and we also take on all revisions to approval for you. Thanks again!